QLoRA and RAG Case Study on PsychoPy with Gemma 2 27B

For the last 2 weeks, I’ve been trying to gather and synthetically generate data to use in fine-tuning and implementing RAG on a series of Google’s open-source Gemma models for PsychoPy. Having successfully curated relatively high-quality data, I’m excited to share my findings in this case study.
Code Generation and Debugging
A common problem, which I’ve experienced and heard from others, is that even flagship LLMs struggle with zero-shot, accurate code generation for psychological experiments. This issue extends to automatic code completion tools like Copilot and Cursor. One feasible solution I found is to fine-tune a capable open-source model with QLoRA for our very specific task of generating psychology experiments.
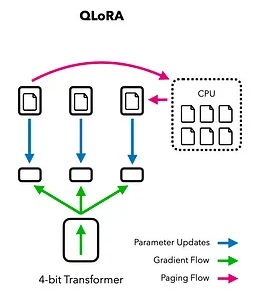
QLoRA is a technique designed to fine-tune large language models efficiently. By utilizing low-rank adaptation matrices and quantizing model weights to 4-bit, while keeping activations and gradients in higher precision, QLoRA allows efficient fine-tuning of originally very large language models on even consumer-grade hardware. This process uses quantization, which reduces the precision of the model weights (from 32-bit to 4-bit), making it possible to fine-tune large models on less powerful hardware without sacrificing much performance. The model retains most of the original model’s capabilities while learning new abilities from the fine-tuning dataset, which in this case is a supervised-instruction dataset.
In this case study, I focused on 3 different use cases for the fine-tuned models:
- zero-shot code generation (Model 1)
- Debugging of common mistakes (Model 1)
- Finding relevant information from a knowledge base (Model 2)
In the next section, I’ll discuss the results of the first two use cases.
Results Model 1
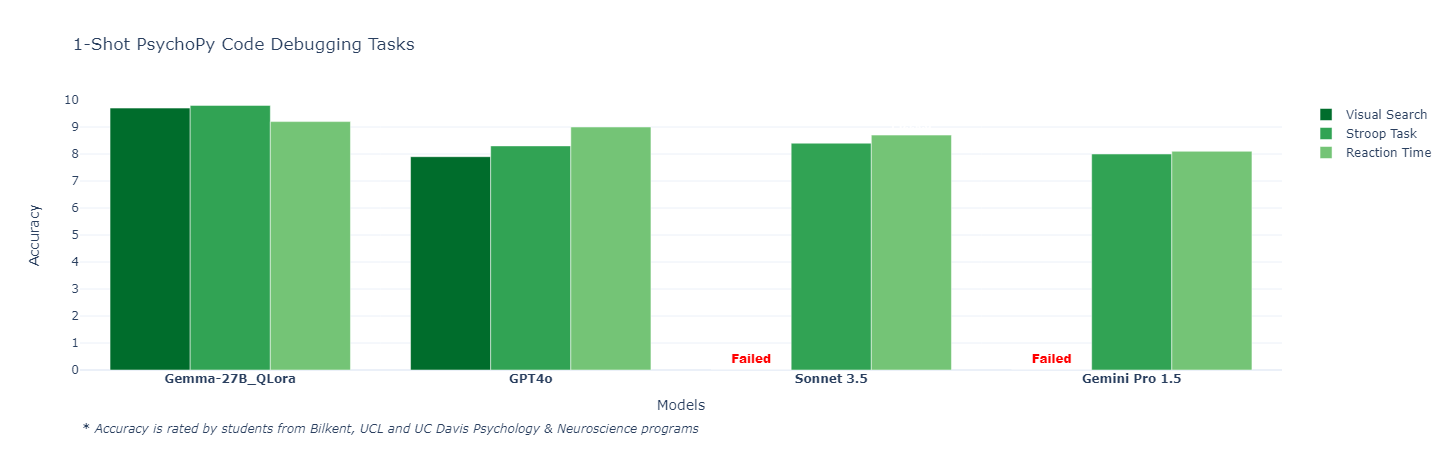
Our first task was zero-shot, prompted, accurate code generation. The model was required to generate correct and functional code with minimal input and iterative prompting. The challenge was to see how well Model 1, the fine-tuned Gemma 2 model, performed compared to flagship models in generating code for PsychoPy experiments from difficult prompts. We asked the models to set up three simple yet essential psychology experiments:
Visual Search Task: A task where participants search for a target item among distractors.
Stroop Task: A cognitive task that requires participants to name the color of a word while ignoring the word itself, which may spell a conflicting color.
Reaction Time Task: Measuring the time it takes for participants to respond to a visual stimulus.
For all these tasks, there were specific details to implement, such as:
-
Colors: The precise color specifications for stimuli in each task (e.g., different colors for target and distractor items in the Visual Search Task, color-word pairs in the Stroop Task).
-
Positions: The exact placement of stimuli on the screen (e.g., random but controlled positions for the Visual Search Task, fixed central positions for the Stroop and Reaction Time Tasks).
-
Timing: The timing parameters for stimulus presentation and response windows.
Results were judged on the accuracy of the initial response by myself and fellow Senior and Graduate students from Neuroscience & Psychology programs all over the world.
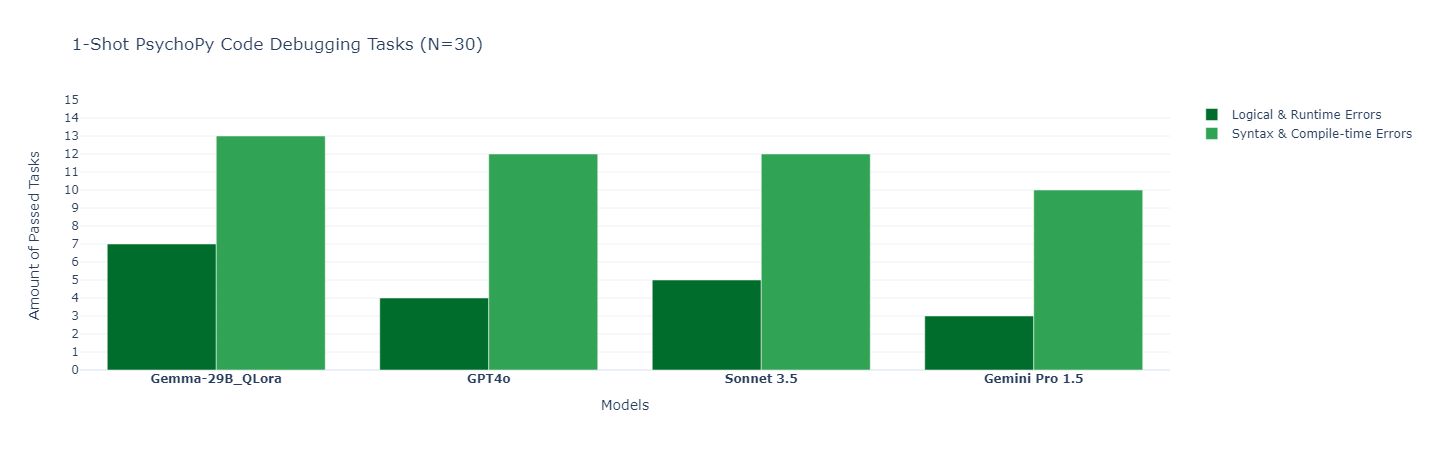
Continuing from the previous section on code generation, the second use case involved debugging faulty code. This task is arguably the most important, as even small mistakes in code can lead to significant issues in psychological experiments. For this task, Model 1 was given snippets of PsychoPy code along with error messages, and its ability to diagnose and correct the errors was tested across 30 different cases, with 15 in each category. Again, this was a zero-shot task hard-prompted, meaning the models had only one chance to fix the mistakes in the snippets with no further context than the prompt. Errors were categorized into two general types:
Logical & Runtime Errors: These errors occur when the code runs but produces unintended behavior or crashes during execution. They can be tricky to spot, as they involve mistakes in the logic of the code, such as incorrect conditional statements, timing issues, or improperly initialized variables.
Syntax & Compile-time Errors: These errors prevent the code from running at all due to mistakes in the code’s structure, such as missing punctuation, incorrect indentation, or invalid function calls. These are generally easier to identify.
Results were judged by myself based on whether the mistake was fixed.
Retrieval-Augmented Generation and Knowledge Bases
One issue I commonly face with flagship LLMs is that they sometimes generate parameters, functions, or other information that might be related to the query but are entirely made up. These are known as hallucinations. While the hallucination problem has significantly improved over the last few years, it remains a common issue, particularly when responding to queries with uncommon representation in the LLM’s training data, such as PsychoPy documentation. Retrieval-Augmented Generation (RAG) offers a solution to this problem. Although not perfect, it significantly reduces the frequency of hallucinations by ensuring that relevant information is pulled from an external source such as a document store or a knowledge base and used to augment the response. This ensures that responses are grounded in the retrieved information. Therefore, if you set up your RAG system well, it can alleviate these issues and provide relevant information in a more complete fashion.
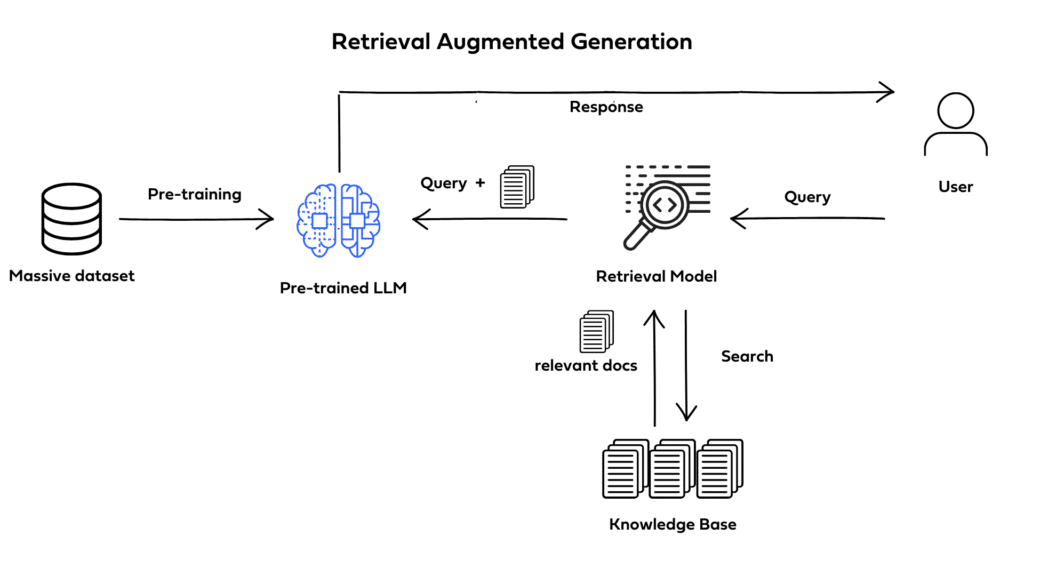
I’ve implemented a fine-tuned Gemma 2 27B model with a RAG system. While RAG frameworks can be complex, I believe more recent iterations have resulted in a well-functioning system. To evaluate its effectiveness, I designed 6 questions to assess the model’s understanding of PsychoPy documentation, best practices, and key features & concepts. These questions focused on clear and complete explanations in text rather than generating code. The quality of the responses was then evaluated by students from Psychology & Neuroscience programs over the world.
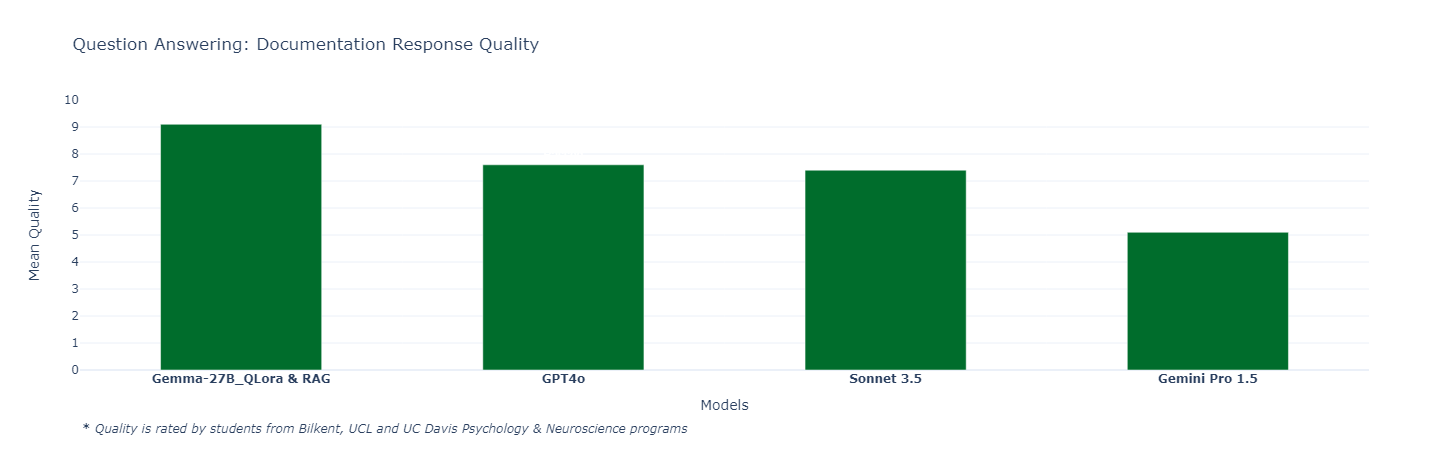
Conclusions
This case study highlights the significant value of fine-tuning and Retrieval-Augmented Generation (RAG) for specialized use cases. While not exhaustive in addressing every potential challenge with the PsychoPy library, it convincingly demonstrates that with a sufficiently large and high-quality dataset, even relatively smaller fine-tuned LLMs (Gemma 2 27B isn’t small, but it’s quantized to 4-bit and is still much smaller compared to flagship models) can outperform state-of-the-art models on spesific tasks (like 0-shot psychopy code generation). The success observed with RAG further underscores this point.
I also wanted to format this case study to reflect the average student’s experience with LLMs. If you are unfamiliar with LLM research, chances are you’re not employing advanced prompting techniques like few-shot reasoning or chain-of-thought prompting, so with zero-shot hard prompts like “Code a visual search task where target is t and distractors are a”, I believe this case study maps well onto the average experience of a non-technical undergrad/grad student interacting with LLMs.
Moreover, I believe there is potential for relatively small, specialized LLMs to be used in class settings or with released libraries, especially if one has the resources for full fine-tuning. Of course, these LLMs will still occasionally hallucinate or make errors, but considering that students already use models prone to even greater inaccuracies, fine-tuned, specialized models could offer a more reliable alternative, especially in classroom settings or for publicly available libraries/frameworks that aren’t well represented in the training data of state-of-the-art models.
Thank you for reading, and thank you to all who participated in rating from all over the world!
Edit 29.09 2024: You can now try out the improved fine-tuned model for yourself if you’d like in 4 and 8 bit quantized GGUF forms on Hugging Face. If you’d like to try it out with no gpu access –> Can use this llama.cpp collab notebook and if you have gpu access or collab pro –> unsloth notebook
An upgraded RAG framework with LangChain on PsychoPy documentation notebook coming soon™(as soon as i find more hobby-project time) as well.